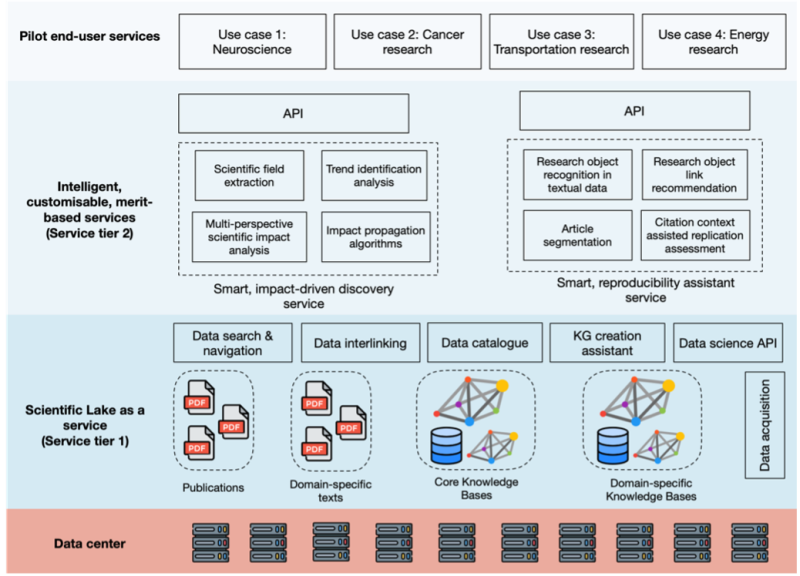
SciLake will develop, support, and offer customisable services to the research community following a two-tier service architecture.

TIER I
Offer a comprehensive, open, transparent, and customisable scientific data-lake-as-a-service, empowering and facilitating the creation, interlinking, and maintenance of SKGs both across and within different scientific disciplines.
TIER II
Build and offer a set of customisable, AI-assisted services that facilitate the navigation of scholarly content following a scientific merit-driven approach, focusing on two merit aspects which are crucial for the research community at large: impact and reproducibility.