In the era of Open Science, it has become crucial to track how scientists conduct their research. The concept of "discovery" has evolved, and now we aim to enable reproducibility and assess the quality of research beyond just publications. The OpenAIRE Graph was developed for this purpose. This graph is a collection of metadata describing various objects in the research life cycle, forming a network of interconnected elements.
Motivation and concept
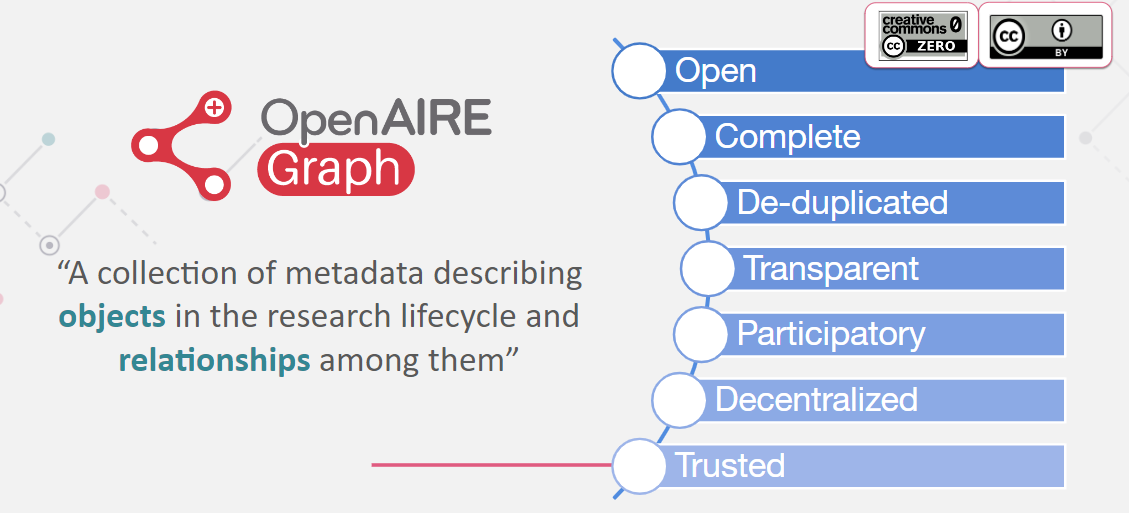
The OpenAIRE Graph aims to be a complete and open collection of metadata describing research objects. It includes data from various big players, such as Crossref, to be as comprehensive as possible. To maintain accuracy, the graph is de-duplicated, meaning that when metadata from different sources are available for the same research result, only one entity is counted for statistical purposes. Transparency is also a key aspect, as provenance information is marked and traced within the graph. Additionally, the OpenAIRE Graph is built to be participatory, allowing anyone to contribute their data following the provided guidelines. The graph also strives to be decentralized, enriching information from repositories and pushing it back to the original sources. By including trusted providers, the graph becomes a valuable resource for researchers throughout the research life cycle.
Data Sources and Data Model
Everyone is free to share their data with the graph by registering on one of our services and sharing the metadata. We currently have more than 2,000 active data sources. These include institutional and thematic repositories, funder databases, entity registries, organizations, ORCID, and many more sources. All the metadata from these different entities are interconnected.
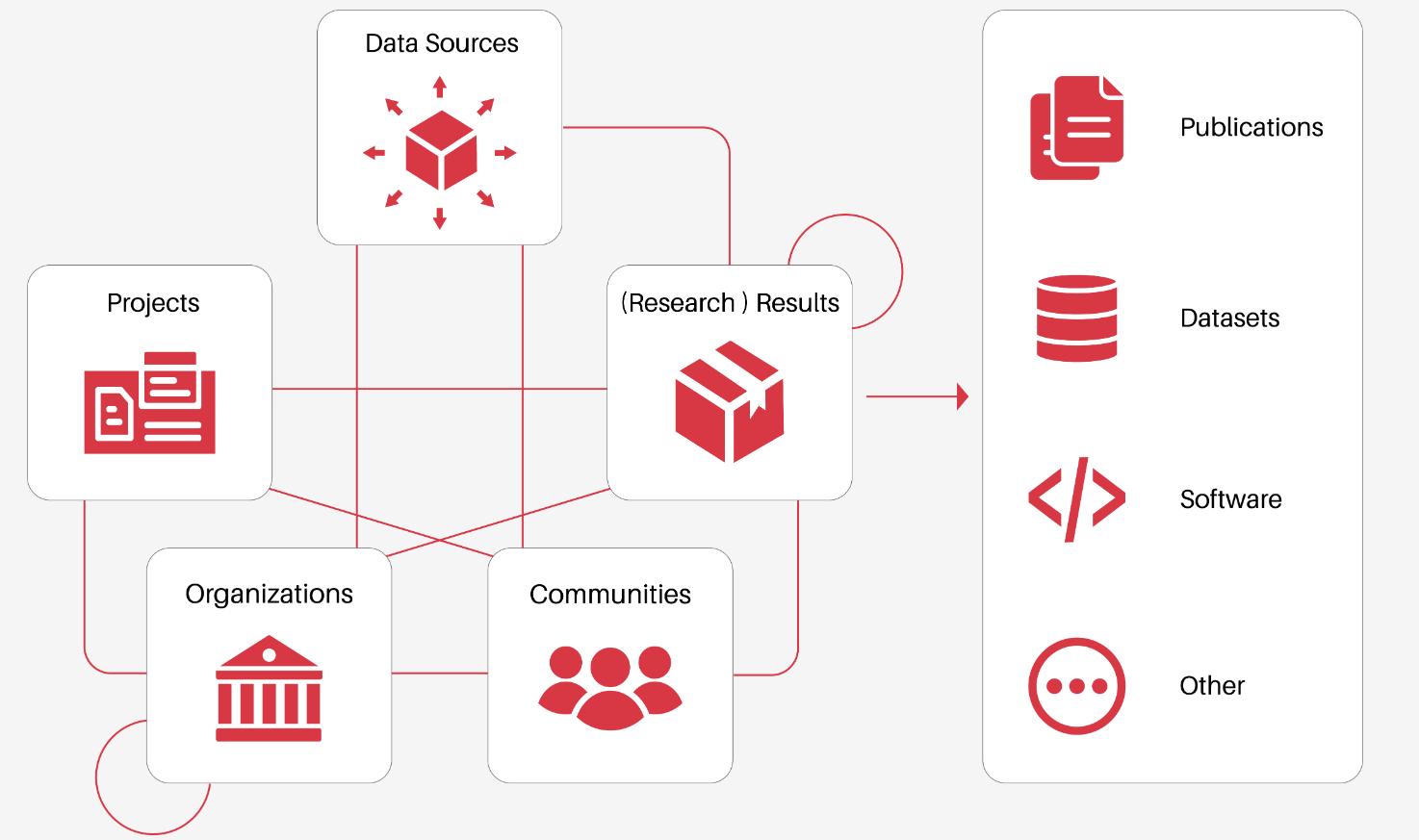
The OpenAIRE Graph Data Model
Building Process
The OpenAIRE Graph is built upon metadata provided voluntarily by data sources. Regular snapshots of the metadata are taken and combined with full-text mining of Open Access publications to enrich the relationships among entities. Duplicates are handled by creating a representative metadata object that points to all replicas. The graph then goes through an enrichment process, utilizing the existing information to further enhance the relationships and results. Finally, the graph is cleaned and indexed, making it accessible through the API and OpenAIRE's value-added services.
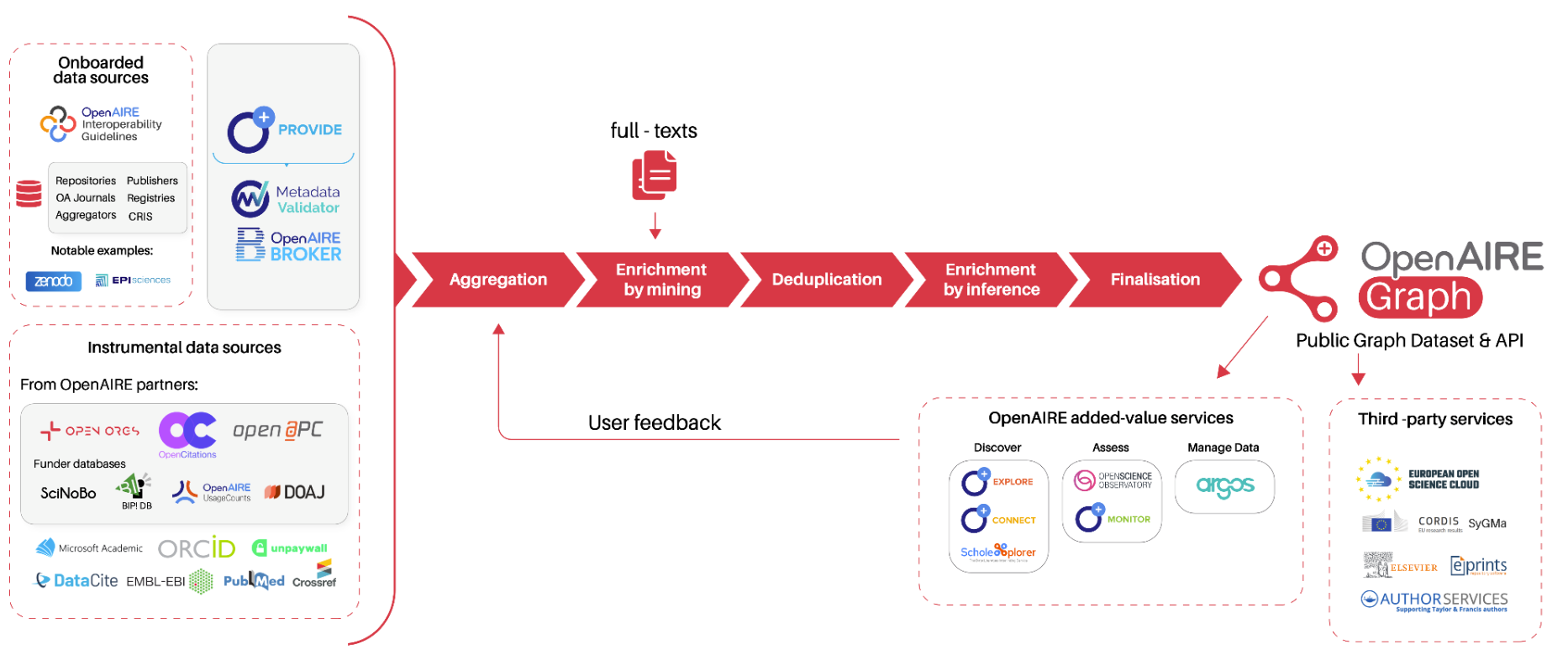
The OpenAIRE Graph supply chain
Connection to Science Communities
The OpenAIRE Graph has significant relevance and connections to various science communities. SciLake's pilots will receive the following benefits:
- For Cancer research, the graph imports metadata from PubMed and plans to integrate citation links between PubMed articles.
- For Energy research, there is already a gateway called enermaps.eu that provides access to relevant information and the graph will add further linkage options.
- For Neuroscience, interoperability options between the OpenAIRE Graph and the EBRAINS-KG will be offered.
- For the Transportation research, two paths are envisaged:
- access products related to the TOPOS gateway (beopen.openaire.eu), which contains all the relevant information for transportation research included in the graph,
- investigate interoperability options between the OpenAIRE Graph and the Knowledge Base on Connected and Automated Driving (CAD)
The OpenAIRE Graph continues to evolve and welcomes ideas and collaborations from all science communities.
Challenges and perspectives
Building and maintaining the OpenAIRE Graph comes with its own set of challenges. Combining domain-specific knowledge with domain-agnostic knowledge can be complex, especially when dealing with unstructured files and non-English texts. The format and organization of data vary across communities, making it difficult and unsustainable to include everything in the graph.
While challenges exist, the SciLake project plays a pivotal role in improving and expanding the OpenAIRE Graph to accommodate new entities ensuring its relevance and usefulness for the scientific community.