
Knowledge Graph: Benefits
The use of a scientific knowledge graph offers several benefits. It empowers research in precision medicine and diagnostics by facilitating the discovery of potential associations between identified biomarkers and other elements, such as genes, biological or functional pathways, and drugs. Furthermore, it is easily deployable and flexible, capable of integrating data from various sources, thereby offering a comprehensive view of the research landscape.
Challenges
Developing a knowledge graph comes with its own set of challenges. The objective is to provide tools for creating and enriching the graph, and the primary concern is extracting latent knowledge to create the graph. Another significant challenge is establishing a common language among people of different expertise, such as clinicians and technical developers. This is crucial to facilitate effective communication and collaboration in the development and application of the knowledge graph. Finally, an important step to validate the graph involves manual curation to assess hidden associations and existing connections and ensure they are relevant to the specific biology experiment.
Where are we
The development of the knowledge graph is progressing by leveraging several pre-existing state-of-the-art knowledge graphs. One is PrimeKG, which is used to query networks of genes or proteins connected to a specific disease. For example, the graph shows connections between CLL and TP53, a gene known for its potential to increase the risk of various forms of cancer significantly when altered. Other larger state-of-the-art knowledge graphs, based on various biomedical databases, are also being integrated along with Prime KG. This strategy aims to capitalise on a broader set of databases and underlying connections, potentially uncovering new missing links. An example of this is the revealed relation between CLL and the gene SOD1, known for being overexpressed in many human cancers.
A variety of knowledge graphs exist, each drawing from a different biomedical source, and we can collect more information through their combination. In fact, many details are unique to a particular graph and there is minimal overlap between them.
Our data flow involves using a variety of knowledge graphs, including those previously mentioned, along with different ontologies and other data sources. We utilize tools provided by SciLake to establish connections among them and generate a comprehensive cancer knowledge graph.
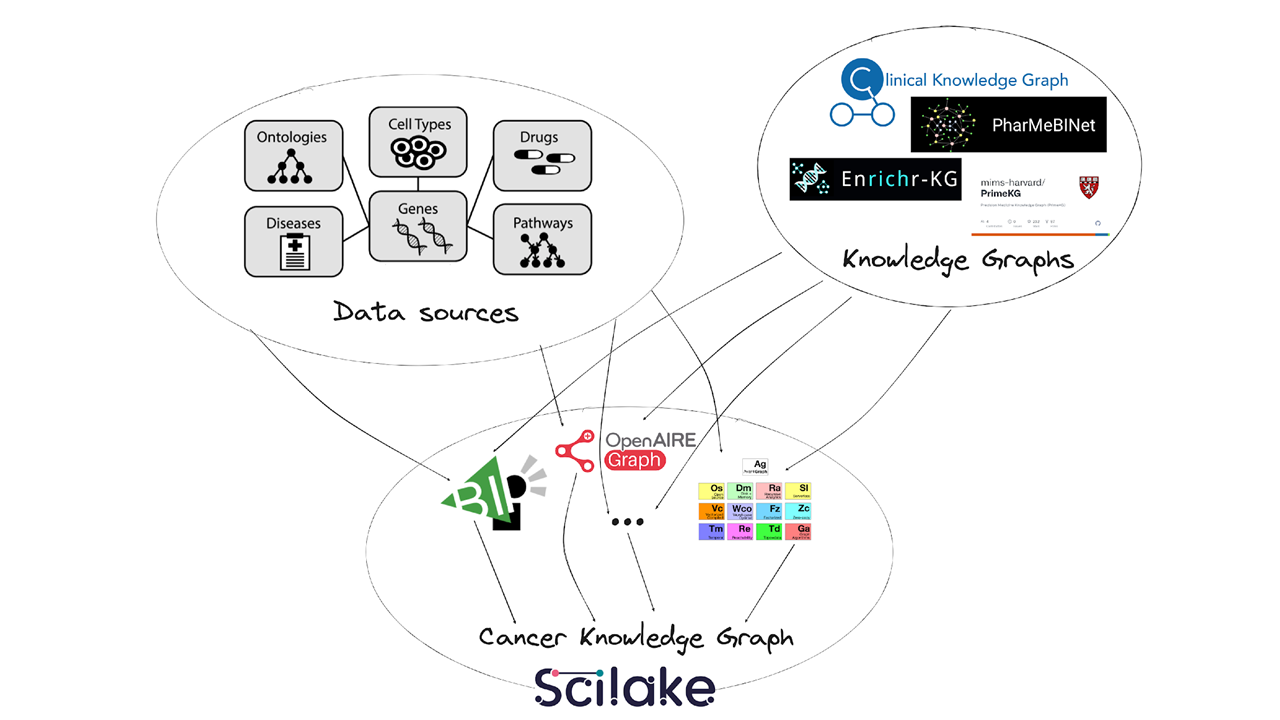
Dataflow towards a CLL KG