- Service Component Info:
- Data catalogue, Service Component Intro:
A data catalog is an organized inventory of resources. It leverages rich metadata descriptions to support data discovery and governance. It is a single point of access for all the relevant resources, independent of the place they are stored or running. , Service Component Logo:
 , Service Component Motto:
Enriching research through comprehensive resource description
, Service Component Motto:
Enriching research through comprehensive resource description
- SC Contact:
- SC Contact Person:
Miriam Baglioni, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Users:
- Service Component Users:
Research Communities
- Service Component Users:
Service Providers
- SC Organisations:
- SC Features:
- SC Features Name:
Discovery, SC Features Desc:
Allows to find resources and verify the license conditions
A data catalog is an organized inventory of resources. It leverages rich metadata descriptions to support data discovery and governance. It is a single point of access for all the relevant resources, independent of the place they are stored or running.
- Service Component Info:
- Information Inference Service, Service Component Intro:
Information Inference Service (IIS) is a flexible data processing system for handling big data based on Apache Hadoop technologies. It is a subsystem of the OpenAIRE system and it uses algorithms to extract new entities and relations from full texts to enrich SKGs. , Service Component Logo:
 , Service Component Motto:
Enhancing metadata through text and data mining,
, Service Component Motto:
Enhancing metadata through text and data mining, In practice, IIS defines data processing workflows that connect various modules, each one with well-defined input and output.
A high-level overview of IIS can be found in the paper “Information Inference in Scholarly Communication Infrastructures: The OpenAIREplus Project Experience", Procedia Computer Science, vol. 38, 2014, 92-99”.
Documentation: Enrichment by mining | OpenAIRE Graph Documentation
Publications:
- Fedoryszak, M., Tkaczyk, D., Bolikowski, Ł. (2013). Large Scale Citation Matching Using Apache Hadoop. In: Aalberg, T., Papatheodorou, C., Dobreva, M., Tsakonas, G., Farrugia, C.J. (eds) Research and Advanced Technology for Digital Libraries. TPDL 2013. Lecture Notes in Computer Science, vol 8092. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-40501-3_37
- Giannakopoulos, T., Stamatogiannakis, E., Foufoulas, I., Dimitropoulos, H., Manola, N., Ioannidis, Y. (2014). Content Visualization of Scientific Corpora Using an Extensible Relational Database Implementation. In: Bolikowski, Ł., Casarosa, V., Goodale, P., Houssos, N., Manghi, P., Schirrwagen, J. (eds) Theory and Practice of Digital Libraries -- TPDL 2013 Selected Workshops. TPDL 2013. Communications in Computer and Information Science, vol 416. Springer, Cham. doi:10.1007/978-3-319-08425-1_10
- P. J. Dendek, A. Czeczko, M. Fedoryszak, A. Kawa, and L. Bolikowski, "Content Analysis of Scientific Articles in Apache Hadoop Ecosystem", Stud. Comp.Intelligence, vol. 541, 2014.
- Foufoulas, Y., Zacharia, E., Dimitropoulos, H., Manola, N., Ioannidis, Y. (2022). DETEXA: Declarative Extensible Text Exploration and Analysis. In: , et al. Linking Theory and Practice of Digital Libraries. TPDL 2022. Lecture Notes in Computer Science, vol 13541. Springer, Cham. doi:10.1007/978-3-031-16802-4_9
- Foufoulas Y., Stamatogiannakis L., Dimitropoulos H., Ioannidis Y. (2017) “High-Pass Text Filtering for Citation Matching”. In: Kamps J., Tsakonas G., Manolopoulos Y., Iliadis L., Karydis I. (eds) Research and Advanced Technology for Digital Libraries. TPDL 2017. Lecture Notes in Computer Science, vol 10450. Springer, Cham. doi:10.1007/978-3-319-67008-9_28
- Dominika Tkaczyk, Pawel Szostek, Mateusz Fedoryszak, Piotr Jan Dendek and Lukasz Bolikowski. CERMINE: automatic extraction of structured metadata from scientific literature. In International Journal on Document Analysis and Recognition, 2015, vol. 18, no. 4, pp. 317-335, doi: 10.1007/s10032-015-0249-8.
- SC Contact:
- SC Contact Person:
Marek Horst, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Users:
- Service Component Users:
Content Providers
- Service Component Users:
Research Communities
- Service Component Users:
Research Organisations
- Service Component Users:
Innovators
- Service Component Users:
Funders & Policy Makers
- SC Organisations:
- SC Features:
- SC Features Desc:
Enhance metadata with information obtained through text and data mining
- SC Features Desc:
Improved linked open science
- SC Features Desc:
Improved research analytics
- SC Features Desc:
Improved research monitoring and impact assessment
- SC Features Desc:
Customers get structured metadata related to the publications
- SC Features Desc:
Funders have access to a list of publications that acknowledge their projects
- SC Features Desc:
Content providers (Repository managers/ OA publishers) may enrich their content
Information Inference Service (IIS) is a flexible data processing system for handling big data based on Apache Hadoop technologies. It is a subsystem of the OpenAIRE system and it uses algorithms to extract new entities and relations from full texts to enrich SKGs.
- Service Component Info:
- KG creation assistant & Interlinking, Service Component Intro:
The Knowledge Graph creation assistant & Interlinking tool is designed to extract knowledge graphs from unstructured or semi-structured data sources and enrich their content. , Service Component Logo:
 , Service Component Motto:
Discovering Dependencies, Enriching Knowledge,
, Service Component Motto:
Discovering Dependencies, Enriching Knowledge, Through the use of the GGDminer tool, it aims to discover Graph Generating Dependencies (GGDs) and showcase information about the graph's content. This process involves applying topological and differential constraints to generate meaningful dependencies.
Publications:
- L.C. Shimomura, G. Fletcher, & N. Yakovets (2023) ProGGD - Data Profiling on Knowledge Graphs using Graph Generating Dependencies. International Workshop on the Semantic Web. URL link
- Stoica, Radu, George HL Fletcher, and Juan F. Sequeda. "On Directly Mapping Relational Databases to Property Graphs." AMW 2019. URL link
- SC Contact:
- SC Contact Person:
Nick Yakovets, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Users:
- Service Component Users:
Service Providers
- Service Component Users:
Research Communities
- SC Organisations:
- SC Features:
- SC Features Name:
Data Interlinking, SC Features Desc:
GGDs as prescription rules for data interlinking
- SC Features Name:
Relational to graph schema mapping, SC Features Desc:
Mapping of relational schemas to property graphs towards KG creation
- SC Features Name:
Understanding the KG, SC Features Desc:
GGDs as description rules to drive KG creation
The Knowledge Graph creation assistant & Interlinking tool is designed to extract knowledge graphs from unstructured or semi-structured data sources and enrich their content.
- Service Component Info:
- Open API, Service Component Intro:
Open API is an initiative that aims to hide technical complexities and provide a user-friendly interface for accessing information. , Service Component Logo:
, Service Component Motto:
Simplifying access to knowledge,
Coming Soon
- SC Contact:
- SC Contact Person:
Nick Yakovets, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Users:
- Service Component Users:
Research Communities
- Service Component Users:
Service Providers
- SC Organisations:
- SC Features:
- SC Features Name:
Coming soon
Open API is an initiative that aims to hide technical complexities and provide a user-friendly interface for accessing information.
- Service Component Info:
- PDFfetcher, Service Component Intro:
PDFfetcher is a tool designed to acquire the full text of publications by collecting PDFs from URL links. With a coverage of over 20 million PDF articles, it provides a comprehensive resource for researchers. , Service Component Logo:
 , Service Component Motto:
Unlocking knowledge through PDF acquisition, http://scinem.imsi.athenarc.gr/,
, Service Component Motto:
Unlocking knowledge through PDF acquisition, http://scinem.imsi.athenarc.gr/, Publications:
- P. Koloveas, S. Chatzopoulos, C. Tryfonopoulos, T. Vergoulis (2023) BIP! NDR (NoDoiRefs): A Dataset of Citations From Papers Without DOIs in Computer Science Conferences and Workshops, doi: https://doi.org/10.48550/arXiv.2307.12794
- SC Contact:
- SC Contact Person:
Claudio Atzori, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Contact Person:
Miriam Baglioni, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Contact Person:
Marek Horst, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Users:
- Service Component Users:
Research Communities
- Service Component Users:
Service Providers
- SC Organisations:
- SC Features:
- SC Features Name:
Coming soon
PDFfetcher is a tool designed to acquire the full text of publications by collecting PDFs from URL links. With a coverage of over 20 million PDF articles, it provides a comprehensive resource for researchers.
Workshop
SciLake at GRADES-NDA ’24
By Stefania Amodeo, Daan de Graaf
SciLake recently participated in the 7th Joint Workshop on Graph Data Management Experiences Systems (GRADES) and Network Data Analytics (NDA), held on June 14, 2024, in Santiago, AA, Chile. This prestigious event unites researchers from academia, industry, and government sectors worldwide to discuss and share the latest breakthroughs in large-scale graph data management and graph analytics systems. It also provides a platform to discuss novel methods and techniques to address domain-specific challenges in real-world graphs.
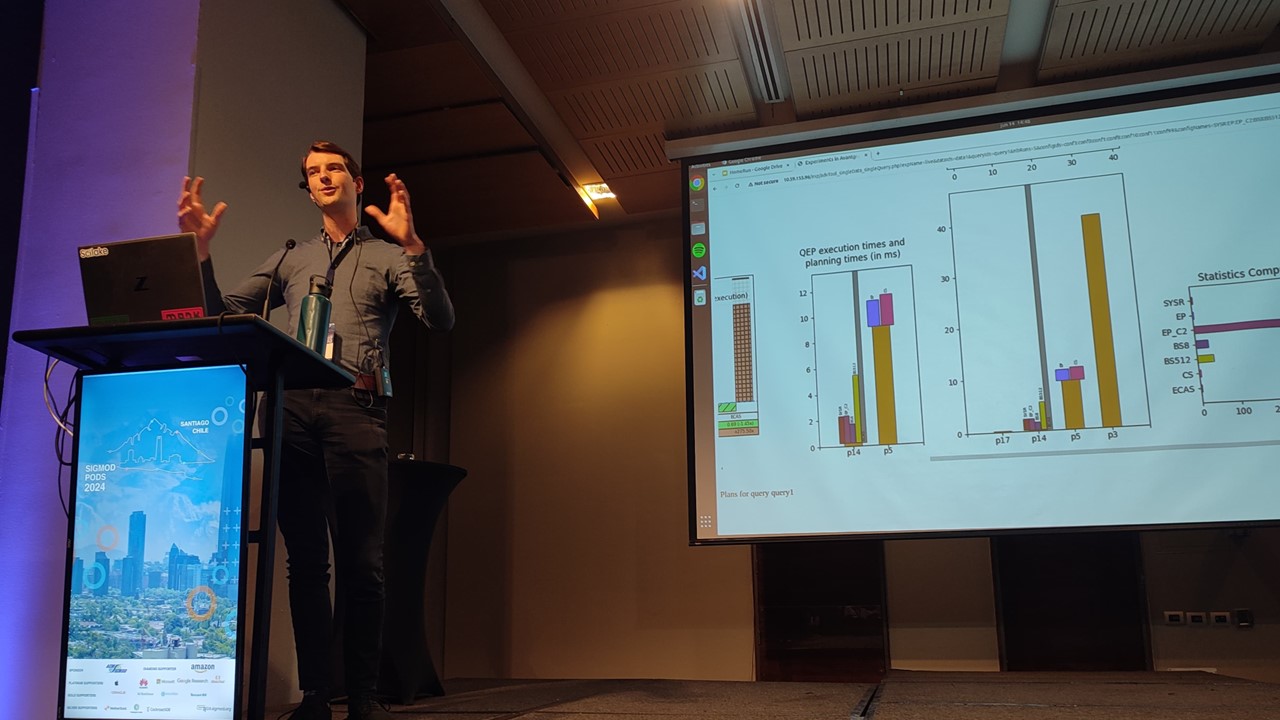
Daan de Graaf (TU/e) at GRADES-NDA ‘24
Our SciLake partner, Daan de Graaf, had the opportunity to present an accepted article on behalf of authors Wilco van Leeuwen, George Fletcher, and Nikolay Yakovets, all from Eindhoven University of Technology (TU/e). The team showcased "HomeRun", a tool specifically designed for comparing different cardinality estimation techniques in graph databases.
For those new to the topic, the cardinality of a graph database refers to the number of elements in a set, such as the number of edges connected to a node or the total number of nodes in the database. Accurate cardinality estimation is crucial for optimising the performance of queries, as it helps plan the most efficient way to retrieve data.
One of HomeRun's key features is its ability to evaluate the performance of different cardinality estimation techniques in given usage scenarios. The tool generates visualisations automatically, helping users understand the trade-offs between various techniques. This tool is particularly useful for database developers when they face performance issues, like long-running queries, with specific query and dataset combinations.
In SciLake, HomeRun is being used to optimise the database system performance in the context of the WP2 Data Lake Search and Navigation.
For more information about HomeRun, you can refer to the paper:
- Wilco van Leeuwen, George Fletcher, and Nikolay Yakovets. 2024. HomeRun: A Cardinality Estimation Advisor for Graph Databases. In Proceedings of the 7th Joint Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA) (GRADES-NDA '24). Association for Computing Machinery, New York, NY, USA, Article 6, 1–9. https://doi.org/10.1145/3661304.3661902
- Service Component Info:
- SciNem, Service Component Intro:
SciNeM is data science tool for metapath-based querying and analysis of Heterogeneous Information Networks. It enables entity ranking, similarity searches, and community detection. , Service Component Logo:
, Service Component Motto:
Data Science Tool for Heterogeneous Network Mining, http://scinem.imsi.athenarc.gr/,
SciNeM is a data science tool for metapath-based querying and analysis of Heterogeneous Information Networks (HINs). It currently supports the following operations, given a user-specified metapath:
- ranking entities using a random walk mode,
- retrieving the most similar pairs of entities,
- finding the most similar entities to a query entity, and
- discovering entity communities via several community detection algorithms.
All supported operations have been implemented in a scalable manner, utilising Apache Spark for scaling out through parallel and distributed computation. SciNeM has a modular architecture making it easy to extend it with additional algorithms and functionalities. Moreover, it provides an intuitive, Web-based user interface to build and execute complex constrained metapath-based queries and to explore and visualise the corresponding results.
URL: http://scinem.imsi.athenarc.gr/
Publications: https://doi.org/10.5441/002/edbt.2021.76
- SC Contact:
- SC Contact Person:
Serafeim Chatzopoulos, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Contact Person:
Thanasis Vergoulis, SC Contact Mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
- SC Users:
- Service Component Users:
Research Communities
- Service Component Users:
Research Managers
- Service Component Users:
Research Organisations
- Service Component Users:
Innovators
- Service Component Users:
Funders & Policy Makers
- SC Organisations:
- SC Features:
- SC Features Name:
Ranking, SC Features Desc:
Assigns centrality scores to entities in a graph using a random walk mode.
- SC Features Name:
Similarity search, SC Features Desc:
Identifies most similar entities to a given entity.
- SC Features Name:
Community detection, SC Features Desc:
Discovers communities of entities in the graph.
SciNeM is data science tool for metapath-based querying and analysis of Heterogeneous Information Networks. It enables entity ranking, similarity searches, and community detection.
 , Service Component Motto:
High-performance graph analytics, https://avantgraph.io/,
, Service Component Motto:
High-performance graph analytics, https://avantgraph.io/,  , SC Org URL:
Eindhoven University of Technology
, SC Org URL:
Eindhoven University of Technology